Does Reasoning Give a Language Model a Personality?
Within-Model Effects of Thinking on Big Five Trait Scores and Construct Validity
In plain language
When an AI stops to “think,” it answers like a calmer person. It still doesn’t have a personality.
What we did
A lot of today's AI models can “think” before they answer: they write out a private chain of reasoning first, then give you a reply. On many models you can turn that thinking on or off. We wanted to know what that switch does to personality quizzes. So we gave the same AI the same Big Five personality quizzes twice, once with thinking off and once with thinking on, and compared its answers to itself. We did this for 12 models in all: ten open models you can download, one open model that always thinks and can't turn it off, and one commercial model (Claude Haiku) from a different company, as a check. We used four different quizzes, short and long, 290 questions total, and asked each one many times.
What we found
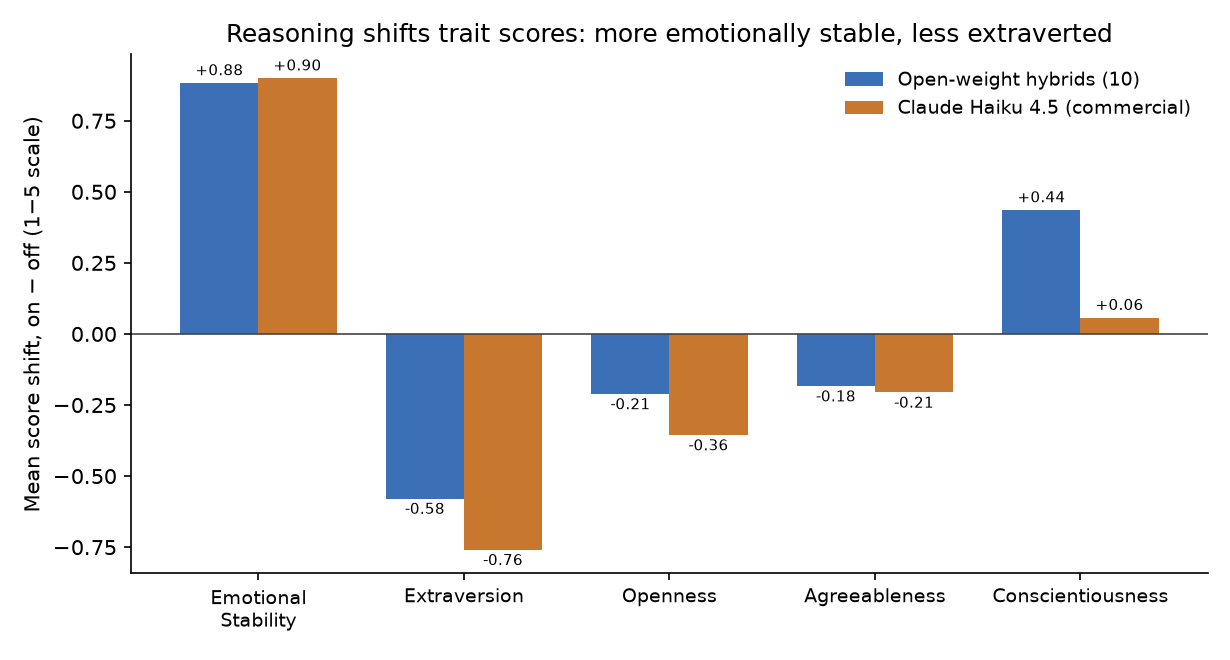
Two clear things. First, thinking changes the answers, and in a consistent direction: the AI reports being calmer and less outgoing when it thinks. The two biggest shifts, more emotional stability and less extraversion, showed up across the downloadable models and again in the commercial model from another company, so it isn't a quirk of one system. (A couple of the other traits moved too, but not dependably enough to hang a claim on, so we don't.) How much a model changes varies: some shift a lot, some barely budge. Second, and this is the heart of it, thinking does not give the AI a real, consistent personality. When you ask one model the same quiz over and over, its answers still don't hang together into a stable profile, whether thinking is off, on, or permanently stuck on. The “personality” still only shows up when you compare many models to each other, not inside any single one.
Why it matters
If you are measuring an AI's “personality,” the thinking setting is not a detail you can ignore: flipping it moves the scores by a noticeable amount, enough to change the story you would tell about that model. And if you were hoping that making a model reason would finally give it a coherent inner character, it doesn't. Reasoning changes what the model says about itself, the way a person might give a more composed answer after a deep breath, without changing the deeper fact that there is no single stable personality underneath.
What this does not mean
It does not mean thinking makes AIs worse, or better, at their real jobs; this is only about personality self-reports. It does not mean the calmer answers are more “honest” or more “fake,” just different. And it does not mean the AI that always thinks is more of a “person” than the others; it showed the same lack of a coherent inner profile as the rest.
A note on how we were careful
For the ten downloadable models, the thinking-off answers came from our earlier study. Before trusting that, we checked it: we re-ran the thinking-off quizzes today and got essentially the same scores as before (within a few hundredths of a point), far smaller than the changes thinking causes. So the comparison is fair.
Words we used
- Big Five
- the standard five personality traits (outgoing, anxious-vs-calm, agreeable, organized, curious).
- Reasoning / thinking
- an AI writing out intermediate steps before answering.
- Emotional stability
- the calm-vs-anxious trait.
- Reliability
- whether a test's answers hang together enough to mean anything.
- Within-model
- looking inside one model's repeated answers, rather than comparing different models.
Abstract
Many current language models generate a chain of “reasoning” tokens before answering, and many expose this as a toggle. Does turning reasoning on change how a model responds to Big Five personality questionnaires? We use a within-model design: the same model answers the same items with thinking off and with thinking on.
We administered four public-domain IPIP Big Five inventories (the 20-item Mini-IPIP, the 50-item IPIP Factor Markers, the 100-item Big Five Aspect Scales, and the 120-item IPIP-NEO, 290 items in total) to ten open-weight hybrid models with a reasoning toggle, one reasoning-native open model (OLMo 3, which cannot disable thinking), and one commercial model (Claude Haiku 4.5, administered through its provider's Batch API). The think-off baseline for the ten hybrids reuses the direct-answer data from our prior study, and we validate that reuse directly: a fresh think-off run reproduces the prior domain means to within 0.07 points on the five-point scale, against reasoning effects 5 to 28 times larger.
Two findings emerge. First, reasoning shifts reported trait scores substantially and in a consistent direction: models present as more emotionally stable (about +0.9 on a 5-point scale) and less extraverted (about −0.6 to −0.8). The two largest effects hold across open-weight and commercial models; the smaller conscientiousness and agreeableness effects do not generalize and are not claimed. Convergent validity rises under reasoning (mean convergent r 0.65 to 0.84) while heterotrait correlation is flat, so the convergent-discriminant gap widens because same-trait agreement rises, not because traits separate. Second, reasoning does not create within-model coherence: treating repeated generations as respondents, internal-consistency reliability stays near zero with thinking off and on (median α near zero; zero of 200 hybrid and zero of 20 commercial model-by-domain cells reach 0.70), and the same holds for the reasoning-native model that cannot stop thinking.
Reasoning changes what a model says about its personality without making that personality cohere as an individual-level property.
Paper & materials
Everything on the table.
The full paper, its source, and the derived data behind every table and figure. The complete raw response databases and all analysis code are archived at Zenodo, under a DOI, so the analysis can be checked, reused, or extended.
-
PDF
main.pdf
The paper itself, typeset. 140 KB.
-
TeX
main.tex
LaTeX source of the typeset paper. 33 KB.
-
MD
draft.md
The paper in Markdown — the readable plain-text version. 21 KB.
-
DOI
Full dataset & code on Zenodo
The complete archive: the raw response databases (think-on, the reused think-off baseline, the reasoning-native arm, and the commercial arm, as SQLite), all administration and analysis code, the four instrument files, and every derived table. DOI 10.5281/zenodo.20974668. CC-BY-4.0.
-
PNG
fig_score_shift.png
Figure: per-domain score shift from thinking off to thinking on, across models. 61 KB.
-
CSV
reasoning_score_delta.csv
Per model × instrument × domain score shift (think-on vs think-off) with bootstrap CIs and Cohen's d, for the ten open-weight hybrids.
-
CSV
reasoning_alpha_paired.csv
Within-model Cronbach's α with thinking off vs on, every model × instrument × domain cell.
-
CSV
reasoning_baseline_repro.csv
Baseline reproducibility check: prior-study think-off means vs. a fresh think-off run, beside the reasoning effect for scale.
-
CSV
haiku_score_delta.csv
The commercial-model arm (Claude Haiku 4.5): score shift off vs on, with CIs and Cohen's d.
-
CSV
haiku_alpha_paired.csv
Within-model α off vs on for the commercial-model arm.
{kind=link}
Cite
Johnson, T. (2026). Does reasoning give a language model a personality? Within-model effects of thinking on Big Five trait scores and construct validity. IFI Research Working Paper. Idea Fields Institute. https://doi.org/10.5281/zenodo.20974668
This is the third in the Institute's series on LLM personality measurement, following the convergent-validity study and the deployment study. Questions, corrections, or replications — research@ideafields.institute.