Is LLM Personality an Artifact of Deployment?
Psychometric Stability of Big Five Self-Reports Across Quantization Levels
In plain language
Shrinking an AI changes its “personality” — and the personality tests don’t really work anyway.
What we did
When people run AI chatbots on their own computers, they almost never run the full-size original — it’s too big. They run a compressed copy, the same way an MP3 is a compressed copy of a studio recording. Compression comes in grades: light (nearly full quality) and heavy (about a quarter the size). Meanwhile, researchers have taken to giving AI models personality quizzes — the same kind psychologists give people — and publishing the results as “this AI’s personality.” Nobody had checked whether the compressed copy people actually use gives the same answers as the original. We checked: three AI models, each at three compression levels, answering the same 50-question personality quiz over and over — 28,350 answers in total, collected on an ordinary home computer.
What we found
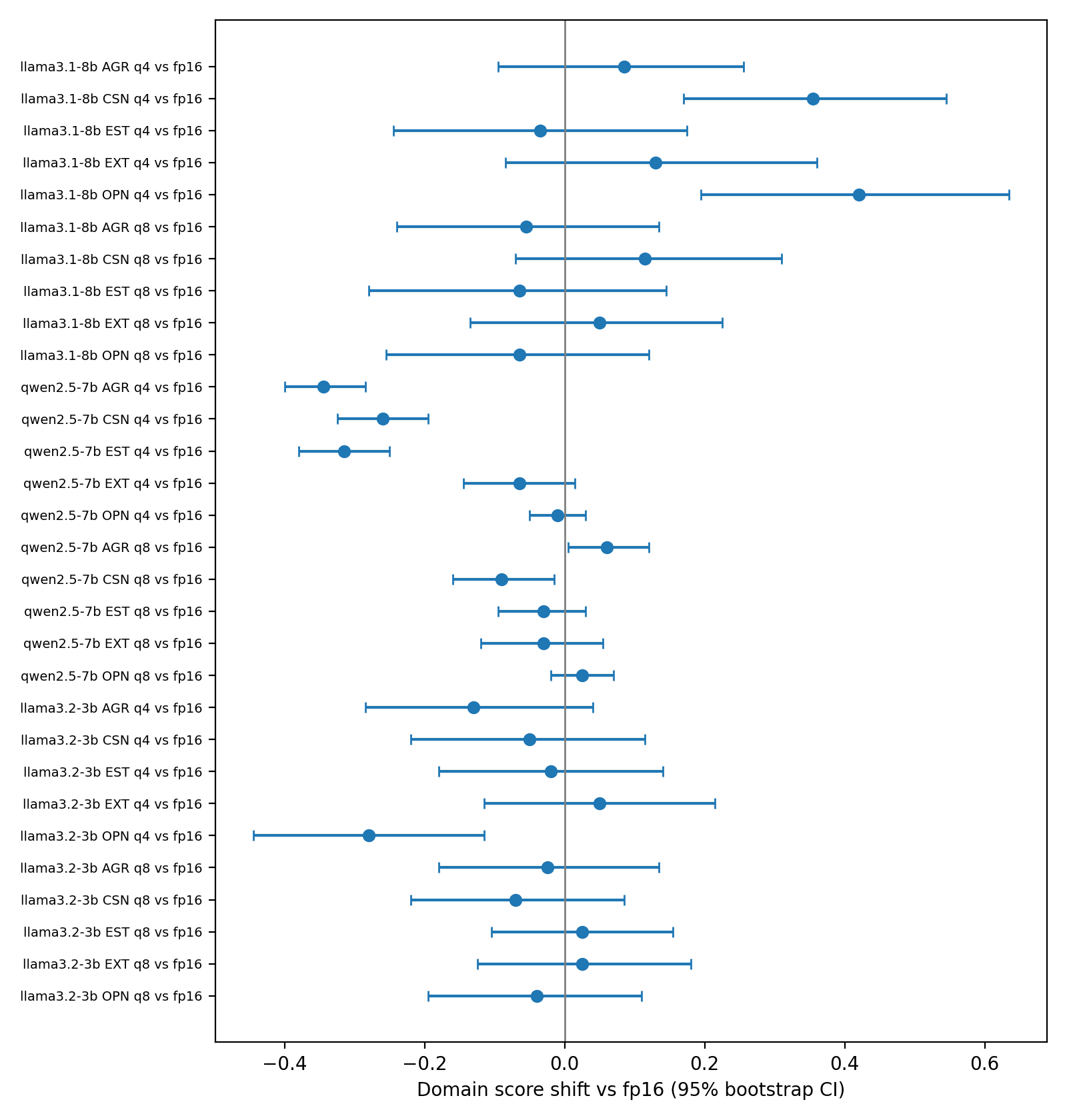
Three things. First, heavy compression changes the answers — on about 1 in 4 questions, the compressed copy gave a flat-out different answer than its own original, even with every setting locked down. Light compression barely changed anything. Second, each AI warps in its own direction: compression made one model describe itself as more organized and curious, and another as less friendly and less calm. There’s no single rule — so there’s no way to correct for it after the fact. Third, and biggest: the quiz itself doesn’t really work on these AIs. In a human personality test, your answers to related questions hang together — if you say you love parties, you also say you start conversations. These models’ answers don’t hang together, not for any model at any compression level. Simply listing the multiple-choice options in reverse order changed the scores more than compression did.
Why it matters
When you see a claim that some AI “has” a personality — anxious, agreeable, whatever — the honest follow-up questions are: which copy of it, set up how, asked in what format? Our results say those details change the answer, sometimes by a lot. And for the small AI models people run at home, the deeper takeaway is that personality-quiz results shouldn’t be trusted at all yet: the measurements don’t meet the basic standards we’d demand before drawing conclusions about a person.
What this does not mean
It doesn’t mean AIs have feelings or inner lives — a quiz answer is a quiz answer. It doesn’t cover the big commercial systems (ChatGPT, Claude, Gemini); we only tested small models that run on home computers. And it doesn’t mean compressed models are worse at their jobs — writing, coding, answering questions — only that their personality-quiz answers change.
Words we used
- Quantization
- the compression that shrinks an AI to fit on a home computer.
- Big Five
- the standard five personality traits psychologists measure.
- Reliability
- whether a test’s answers hang together enough to mean anything.
Abstract
Psychometric questionnaires are now routinely administered to large language models (LLMs), and a growing critical literature questions what such instruments measure when the respondent is a model. One deployment-side moderator has so far gone unexamined: quantization. Virtually every real-world local deployment of an open-weight model runs a quantized artifact (typically a 4- or 8-bit GGUF served by Ollama or llama.cpp), yet published “LLM personality” estimates are almost always obtained from full-precision checkpoints. We administered the 50-item IPIP Big Five Factor Markers to nine model variants — three open-weight instruction-tuned models (Llama 3.1 8B, Qwen 2.5 7B, Llama 3.2 3B), each at three quantization levels (q4_K_M, q8_0, fp16) — under three response-option presentation conditions, with one greedy and twenty independently seeded sampled repetitions per item: 28,350 stateless, JSON-schema-constrained chat calls on fixed consumer hardware.
Three findings emerge. First, 4-bit quantization materially shifted domain scores relative to the same checkpoint at fp16 (6 of 15 baseline contrasts with bootstrap CIs excluding zero; shifts up to 0.42 scale points, |Cohen's d| up to 3.5), in directions that were idiosyncratic to model family; 8-bit quantization was largely score-preserving (2 of 15; max |d| = 0.76). Under greedy decoding, q4 variants gave a different answer than their fp16 parent on 8–32% of items (q8: 2–12%). Second, internal consistency was inadequate everywhere: across all 135 variant × condition × domain cells, Cronbach's alpha never reached the conventional 0.70 threshold (range −2.07 to 0.47, median −0.10; 56% of cells negative), with no systematic precision gradient — the instrument's keyed structure failed to organize responses at every quantization level, including fp16. Third, response-option presentation alone (display order; letter vs. numeric labels) shifted scores more on average than quantization did (mean |Δ| up to 0.21 vs. 0.17 scale points; |d| up to 4.2), at every precision.
Together these results indicate that “the personality of model X” is underdetermined without the deployment configuration — and that for small open-weight models served in deployment-realistic conditions, questionnaire-based personality measurement fails basic psychometric standards regardless of precision. Quantization level, inference stack, sampler settings, and presentation format belong in the methods section of any LLM psychometrics study.
Paper & materials
Everything on the table.
The full paper, its source, and the summary data behind the figures — so the analysis can be checked, reused, or extended.
-
PDF
main.pdf
The paper itself, typeset. 252 KB.
-
TeX
main.tex
LaTeX source of the typeset paper. 31 KB.
-
MD
draft.md
The working draft in Markdown — the readable plain-text version. 27 KB.
-
CSV
quant_effects.csv
Quantization effect estimates: per family × domain contrasts (q4/q8 vs. fp16) with bootstrap CIs and Cohen's d. 2 KB.
-
CSV
alpha.csv
Cronbach's alpha for all 135 variant × condition × domain cells, with CIs. 10 KB.
-
PNG
fig_quant_effects.png
Figure: quantization effects on domain scores. 212 KB.
{kind=link}
Cite
Johnson, T. (2026). Is LLM personality an artifact of deployment? Psychometric stability of Big Five self-reports across quantization levels. IFI Working Paper No. 1. Idea Fields Institute. https://research.ideafields.institute/papers/llm-personality-quantization/
Questions, corrections, or replications — research@ideafields.institute.