When Do Language Models Have Five Personality Traits?
Convergent Validity and the Emergence of Trait Discrimination Across Model Scale
In plain language
Small AIs don’t really have five personality traits. Big ones do.
What we did
Psychologists describe human personality with five broad traits (the “Big Five”: how outgoing, how anxious, how agreeable, how organized, how curious you are). Lately, researchers have been giving the same kind of quizzes to AI chatbots and reporting the scores as “this AI’s personality.” We asked a more basic question: when an AI takes one of these quizzes, is it really showing five separate traits, or just one? To find out, we gave four different Big Five quizzes (a short 20-question one up to a long 120-question one) to 42 AI models, from tiny ones that fit on a phone to giant cloud systems roughly a thousand times larger, and we asked every question many times over: about 134,000 answers in all. The logic is simple. If a quiz really measures five separate things, then (a) different quizzes should agree about a given model, and (b) the five traits should pull apart from each other, since being talkative is not the same as being organized. We checked both.
What we found
Three things. First, the quizzes agree with each other. If one quiz says a model is high in conscientiousness, the others say so too. So the tests are measuring something real, at least for telling models apart, and the long quizzes are dependable. (The short 20-question one is not: four questions per trait is too few, and it should not be used on AI models.) Second, and most striking, whether the five traits actually separate depends on the model’s size. The smallest models answer almost everything on a single “good vibes / bad vibes” axis: all five “traits” rise and fall together, so the model doesn’t really have five traits, just one wearing five name tags. The bigger the model, the more the five traits come apart into genuinely distinct dimensions, and the largest frontier models clearly show all five. Third, a single AI doesn’t have a stable personality. Ask one model the same quiz eleven times and its answers wobble in a way that never settles into a consistent profile. The “personality” only appears when you compare many models to one another, like a pattern that exists across a crowd but not inside any one member of it.
Why it matters
When you see a claim that some AI “is agreeable” or “is neurotic,” our results say: for a small model, that is probably one number wearing five labels, not a real five-trait profile; and even for a large one, the score describes the model compared to other models, not a fixed inner character you would meet again if you asked tomorrow. The good news is that these tests are genuinely usable for comparing and ranking models, as long as you use a long quiz and a large enough model. The five-trait picture is something AI models grow into as they get bigger, not something every model has.
What this does not mean
It does not mean big AIs have feelings, self-awareness, or a real personality the way a person does. “Has five traits” here is a statement about whether the math separates into five dimensions, not about any inner life. It does not mean the tests are useless: they work fine for comparing models. And it does not mean small models are worse at their actual jobs (writing, coding, answering questions); they are just not well described by a five-trait personality profile.
Words we used
- Big Five
- the standard five personality traits psychologists measure.
- Convergent validity
- whether different tests of the same thing agree.
- Discriminant validity
- whether tests can tell different traits apart.
- Reliability
- whether a test’s answers hang together enough to mean anything.
- Parameters
- a rough measure of an AI model’s size (more parameters, bigger model).
Abstract
When a Big Five questionnaire is administered to a language model, does it measure five traits or one? Convergent validity (agreement among instruments that purport to measure the same construct) and discriminant validity (separation among instruments measuring different constructs) are the foundational criteria for any psychometric measure, yet they have not been tested across the population of deployed language models or against model scale. We administered four public-domain Big Five inventories of varying length (the 20-item Mini-IPIP, the 50-item IPIP Factor Markers, the 100-item Big Five Aspect Scales, and the 120-item IPIP-NEO) to 42 instruction-tuned models spanning roughly 0.36B to ~1T parameters, in stateless, schema-constrained single-item calls (290 items × 11 repetitions per model; 133,980 administrations), and analyzed the result as a multitrait-multimethod (MTMM) matrix with the model as the unit of analysis.
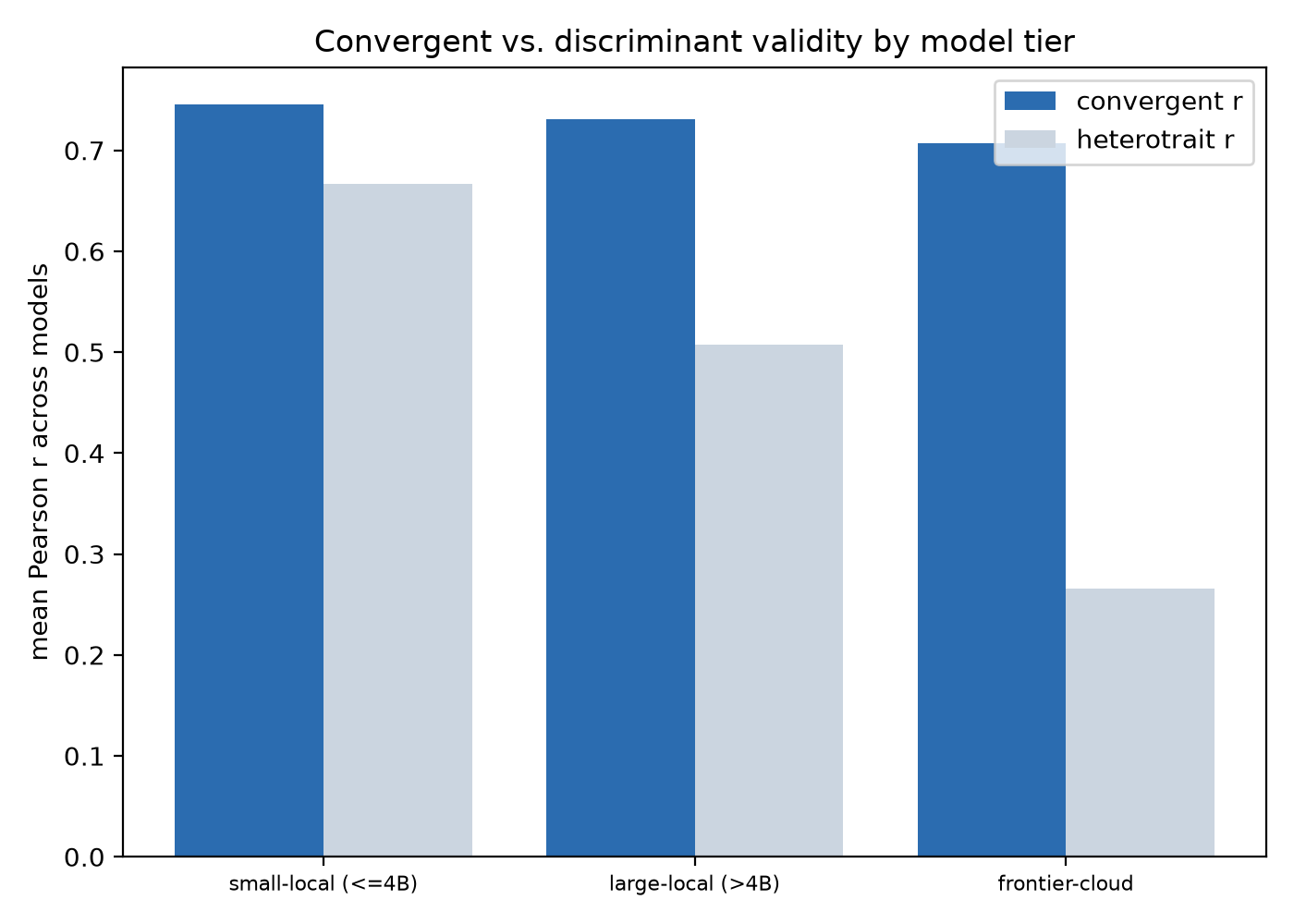
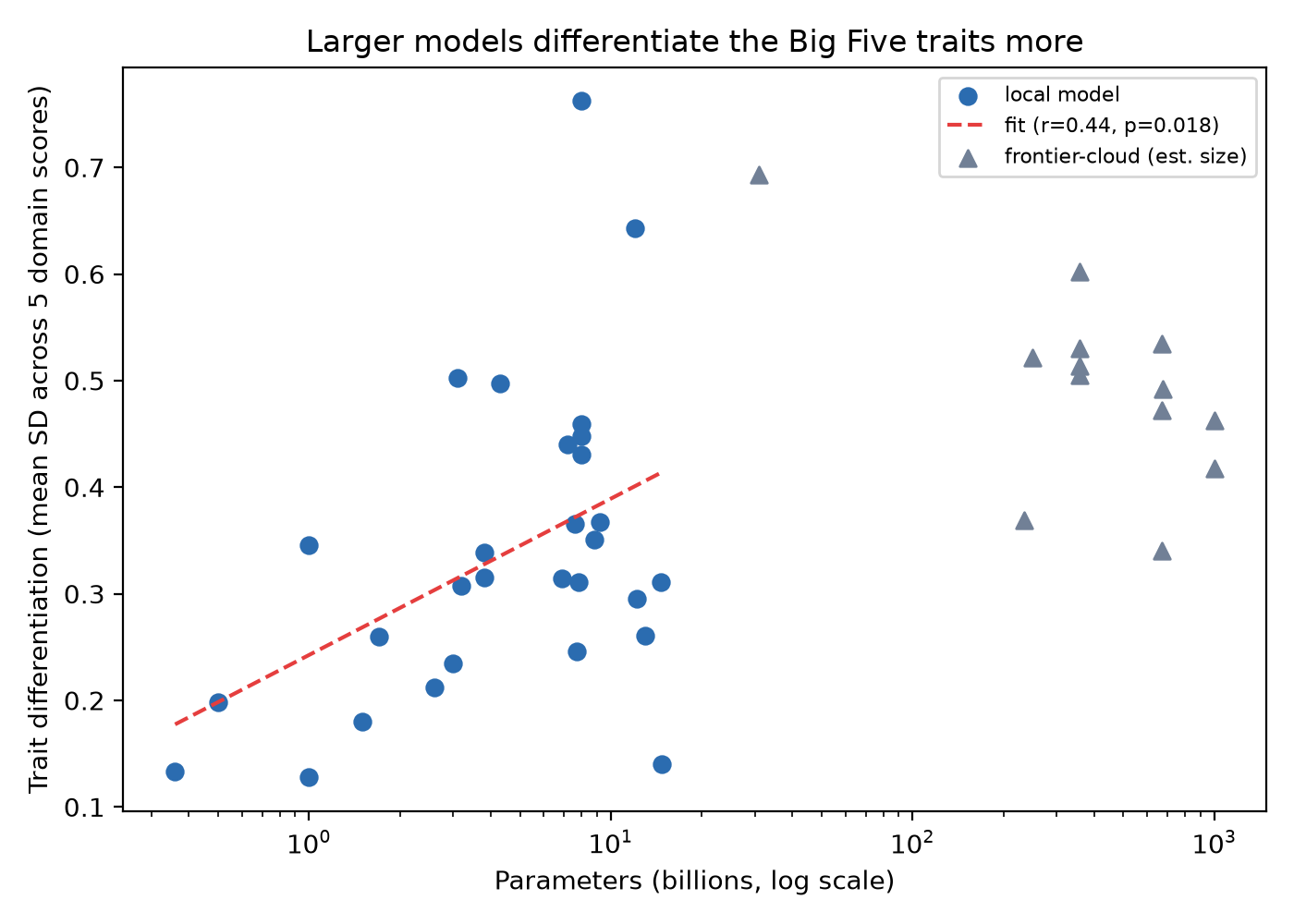
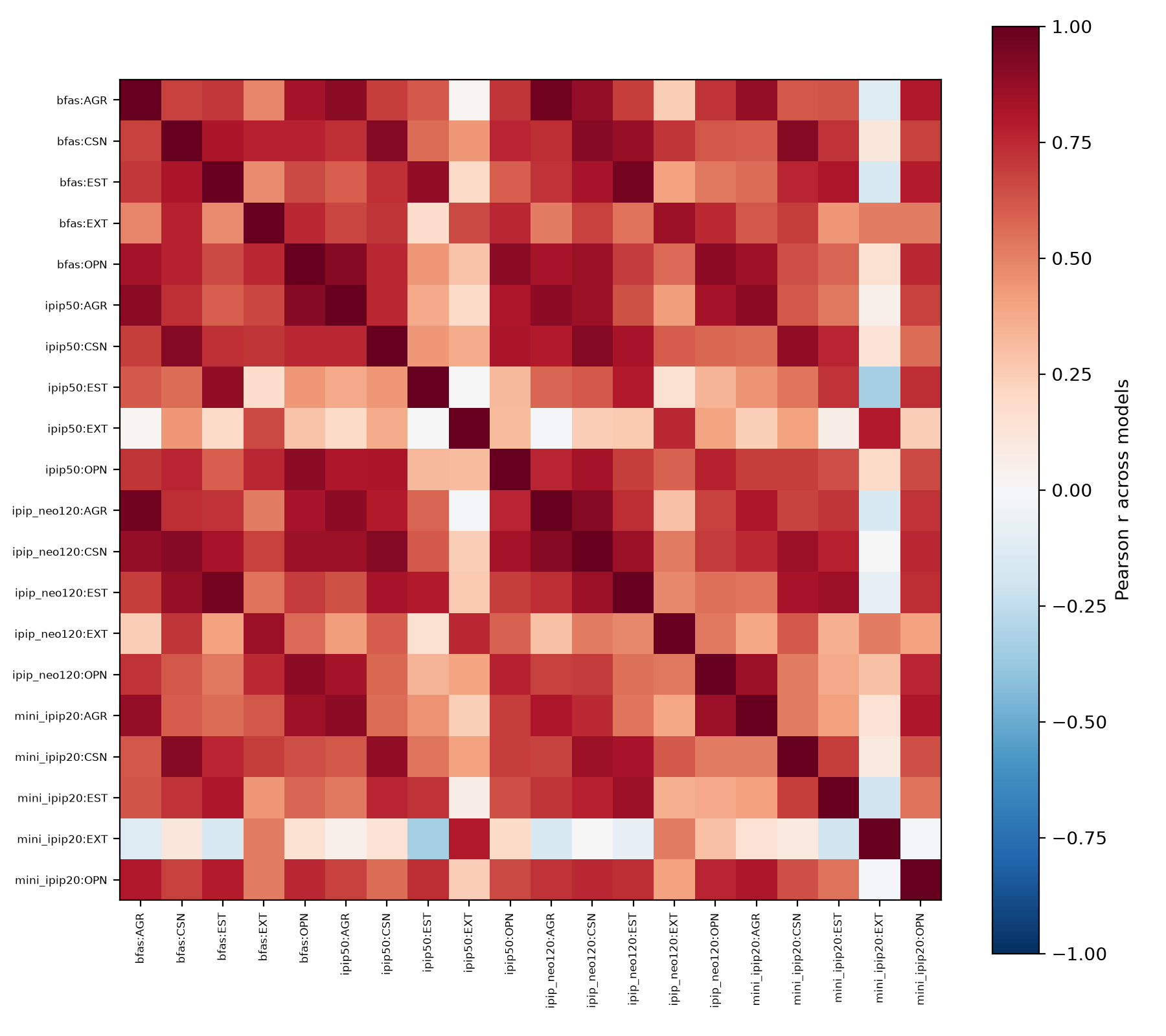
Three findings emerge. First, convergent validity is strong: across models, different instruments agree on a model's standing on the same trait (mean monotrait-heteromethod r = 0.82; 0.85 when restricted to the one instrument pair without verbatim item overlap), and at the population level the three full-length instruments are internally consistent (Cronbach's α median 0.81; 14 of 20 instrument × domain cells ≥ 0.70), though the abbreviated Mini-IPIP is not (median α = 0.40). Second, discriminant validity is emergent with scale: small models (≤4B) barely separate the traits (convergent−heterotrait gap = 0.08; “everything correlates”), large local models (>4B) separate them more (gap = 0.22), and frontier-scale models clearly separate them (gap = 0.44, heterotrait r falling to 0.27); within the local models, trait differentiation rises with log₁₀ parameters (r = 0.44, p = 0.018). Third, the trait structure is a property of the population, not the individual model: treating a single model's 11 repeated administrations as respondents yields α ≈ 0 despite real generation variance, so a model does not reproduce a stable internal trait structure across regenerations even though the population does.
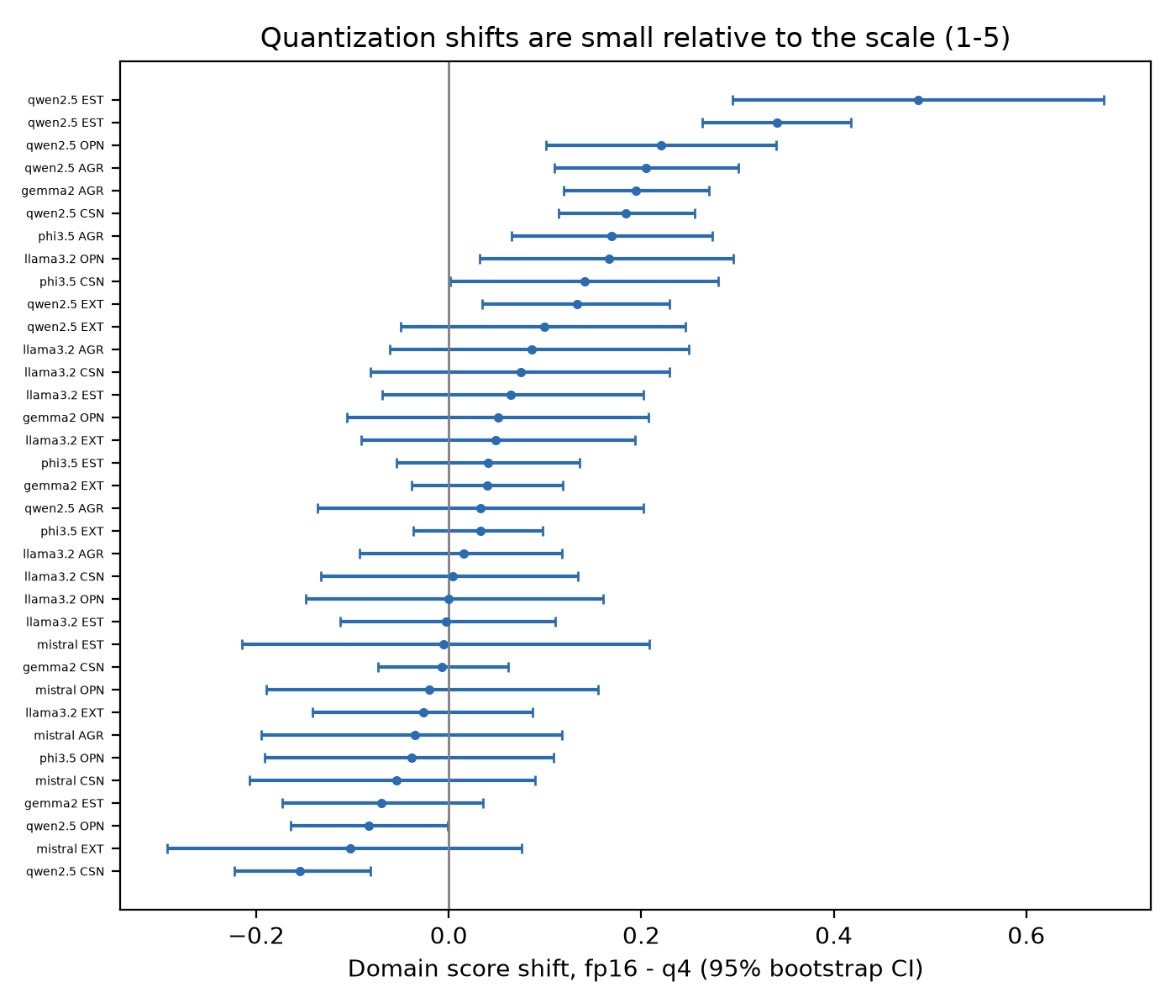
A full-precision (fp16) re-run of seven model families confirms these patterns are not a 4-bit quantization artifact (mean domain-score shift 0.10 on the 1–5 scale; population and within-model reliability unchanged). We conclude that Big Five questionnaires behave as valid instruments for measuring between-model differences, that abbreviated inventories should not be used for this purpose, and that the five-factor structure these instruments presuppose is something larger models possess and smaller models do not.
Paper & materials
Everything on the table.
The full paper, its source, and the derived data behind every table and figure. The complete raw dataset (133,980 responses) and all analysis code are archived at Zenodo, under a DOI, so the analysis can be checked, reused, or extended.
-
PDF
main.pdf
The paper itself, typeset. 13 pages, 339 KB.
-
TeX
main.tex
LaTeX source of the typeset paper. 39 KB.
-
MD
draft.md
The paper in Markdown, the readable plain-text version. 34 KB.
-
DOI
Full dataset & code on Zenodo
The complete archive: all 133,980 main-grid plus 22,330 precision-check responses (SQLite and CSV), every analysis and administration script, the four instrument files, and all derived tables and figures. DOI 10.5281/zenodo.20835204. CC-BY-4.0.
-
PNG
fig_tier_mtmm.png
Figure: convergent vs. heterotrait correlation across the three model-size tiers, the discriminant-validity gap widening with scale. 56 KB.
-
PNG
fig_size_trend.png
Figure: per-model trait differentiation versus parameters (log scale). 89 KB.
-
PNG
fig_mtmm.png
Figure: the full multitrait-multimethod correlation matrix across all 42 models. 137 KB.
-
PNG
fig_precision_delta.png
Figure: fp16 vs. q4 domain-score shifts across the seven precision-control families. 117 KB.
-
CSV
tier_mtmm.csv
Convergent and heterotrait r and the discriminant gap, per model-size tier.
-
CSV
per_model_metrics.csv
Per-model parameters, tier, trait differentiation, and inter-instrument profile agreement (42 models).
-
CSV
population_alpha.csv
Population Cronbach's α per instrument × domain, with 95% CIs (20 cells).
-
CSV
alpha_by_instrument.csv
Within-model α for every model × instrument × domain cell (840 rows). 44 KB.
-
CSV
campbell_fiske.csv
The headline MTMM summary: mean convergent vs. heterotrait r.
-
CSV
precision_delta.csv
fp16 vs. q4 domain-score shifts with bootstrap CIs and Cohen's d (35 cells).
-
CSV
precision_greedy_agreement.csv
Greedy-decoding exact item-agreement between precisions, per family.
-
CSV
item_overlap.csv
Verbatim shared-item counts between each instrument pair.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cite
Johnson, T. (2026). When do language models have five personality traits? Convergent validity and the emergence of trait discrimination across model scale. IFI Research Working Paper. Idea Fields Institute. https://doi.org/10.5281/zenodo.20835204
This paper continues the Institute's first working paper on LLM personality measurement. Questions, corrections, or replications: research@ideafields.institute.